Der letzte Beitrag ist schon eine Weile her, in sofern könnte man diesen Artikel hier auch als eine Art RESET bezeichnen, aber eigentlich soll es darum gehen, wie man bei einem APU-Board einen RESET auf sichere Art und Weise mit einem externen Gerät (zum Beispiel RaspberryPi) auslösen kann, ohne das APU-Board oder andere Komponenten zu gefährden, ohne zufällige Resets zu befürchten und ohne festzustellen, dass der Reset nicht geklappt hat, weil ein Kabel falsch steckt.
Warum das ganze? Bei Freifunk Hochstift möchte man im Rahmen des Out-Of-Band Managements verschiedene APU-Modelle von einem RaspberryPi aus rebooten können. Da die APU sich bei Einschalten der Stromversorgung automatisch einschalten, muss also nur der RESET-Taster automatisiert werden.
Details dazu gibt’s im Vortrag „Out-of-Band-Management für APU-Boards“ beim FreifunkTag19 – Link folgt.
TLDR;
Ich schlage letztlich vor mit möglichst kurzen Kabeln den Reset-Pin und Masse der APU mit einem Relais zu verbinden und darüber den Reset auszulösen, auch wenn es elegantere Lösungen gibt. Warum will ich im Folgenden etwas ausschweifend beantworten. Das ist keine vollständige Einführung in Schaltungsdesign und sicher auch nicht 100% exakt. Hauptaugenmerk liegt auf einer einfachen Erklärung.
Reset und Power-good – was ist das eigentlich?
Das klingt ja erst mal nach einer einfach zu beantwortenden Frage, aber bei genauerer Betrachtung gibt es hier einen Unterschied, der sich auch im Layout der APU-Boards finden lässt, aber dazu später mehr.
Fangen wir mit dem Reset-Signal an. Oder vielmehr damit, was ein Signal eigentlich ist. Mit einem Signal meine ich letztlich nichts weiter als eine „Leiterbahn“ auf der entweder ein HIGH- oder ein LOW-Pegel anliegt. LOW bedeutet, dass das Signal gegenüber GND (idealisiert) eine Spannung von 0V aufweist, HIGH bedeutet, dass eine (positive) Spannung oberhalb eines definierten Pegels anliegt. Vereinfacht: Der Pin wird mittels Widerstand mit Masse oder der Versorgungsspannung verbunden. Mehr dazu siehe: Logikpegel.
Das Reset-Signal dient wenig überraschend dazu, den Prozessor und ggf. weitere Peripherie wie USB-Interface, PCI-Karten, etc. in einen definierten Zustand zu versetzen. Bei einer CPU würde dies bedeuten, dass alle Register gelöscht und der Programmcounter auf die Startadresse, üblicherweise auch 0, gesetzt wird. Der Reset tut also was man erwartet: Alles beginnt bei 0, es ist tatsächlich wie nach dem Einschalten des Systems, weil beim Einschalten genau das passiert: Üblicherweise wird beim Einschalten der Spannungsversorgung der RESET-Pin oder das RESET-Signal für eine bestimmte Zeit „aktiv“ geschaltet. Aber Achtung – beim RESET# handelt es sich in aller Regel um ein active-low Signal! Das bedeutet, dass es aktiv ist, wenn es LOW ist (ach!) – ein Reset wird also ausgelöst, wenn der Pin ‚auf Masse gezogen‘ ist, also mit GND verbunden wird. In Schaltplänen und Datenblättern wird dies meistens durch einen Strich über dem Namen des Signals kenntlich gemacht, bei den APU-Boards hat man sich für eine Raute (#) hinter dem Namen des Signals entschieden.
Das Power-good-Signal ist hauptsächlich bei der Initialisierung eines Systems, also beim Einschalten der Spannungsversorgung von großer Bedeutung. In der Regel sind auf einer Systemplatine verschiedene Komponenten vorhanden, die unterschiedliche Versorgungsspannungen benötigen. Typische Spannungen sind 1.8V, 3.3V, 5V, etc.. Diese Spannungen stehen aber nicht direkt mit dem Einschalten zur Verfügung, im einfachsten Fall kann man sich das so vorstellen, dass erst verschiedene Kondensatoren geladen sein müssen, bis die Spannungsregler funktionieren und eine stabile Ausgangsspannung zur Verfügung stellen können. Es ist auch keine Seltenheit, dass eine 1.8V Spannung aus den 3.3V abgeleitet wird, also zunächst der 3.3V Rail stabil sein muss. Man muss kein Experte sein um festzustellen, dass in dieser Phase das System noch nicht benutzbar ist.
Das Power-good Signal kann auch benutzt werden, um das System anzuhalten oder zurückzusetzen, wenn die Betriebsspannung unter eine kritische Marke fällt.
Power-on-Sequenz
Was passiert also beim Einschalten? Nun, RESET# wird auf Masse gehalten bis die Spannungsversorgung stabil und das Power-good Signal aktiv ist. Man erkennt: beide Signale lassen sich prinzipiell zusammenlegen, weil beide zunächst auf LOW liegen und nach einer kurzen Zeit HIGH gehen sollen. Die APU1 tut auch genau das.
Im einfachsten Fall kann dies über einen Kondensator erfolgen, der über einen kleinen Widerstand aufgeladen wird. Ein Problem kann hier schnelles Aus- und Wiedereinschalten sein – da der Kondensator dann noch geladen ist und kein RESET erfolgt. Wer dazu mehr wissen will sucht nach Schmitt-Trigger und schaut sich die Ladekurve eines Kondensators an.
In der Praxis überlässt man das daher meistens einem designierten Chip, der die Spannungsversorgung überwacht und ein Reset verlässlich auslöst, auch wenn die Spannungsversorgung nur kurz unterbrochen wird oder es zu einem Absinken (Brown-out) der Betriebsspannung kommt. Einige CPUs, gerade im Embedded Bereich, haben Funktionen für den RESET aber auch eingebaut, ansonsten ist das die Aufgabe des Powermanagements.
APU-Board Designs
Im Folgenden betrachte ich jeweils Auszüge aus den Schaltplänen der APU1C/1D und APU2C/2D.
Hinweise zum Lesen: Die Schaltpläne sind auf mehrere Seiten verteilt, daher ist es üblich die Signalnamen zu annotieren und durch die Pfeilrichtung anzudeuten, ob es sich um ein eingehendes oder ausgehendes Signal handelt. Neben dem Signalnamen sind dann noch die Seiten im pdf angegeben, auf denen das Signal noch vorkommt.
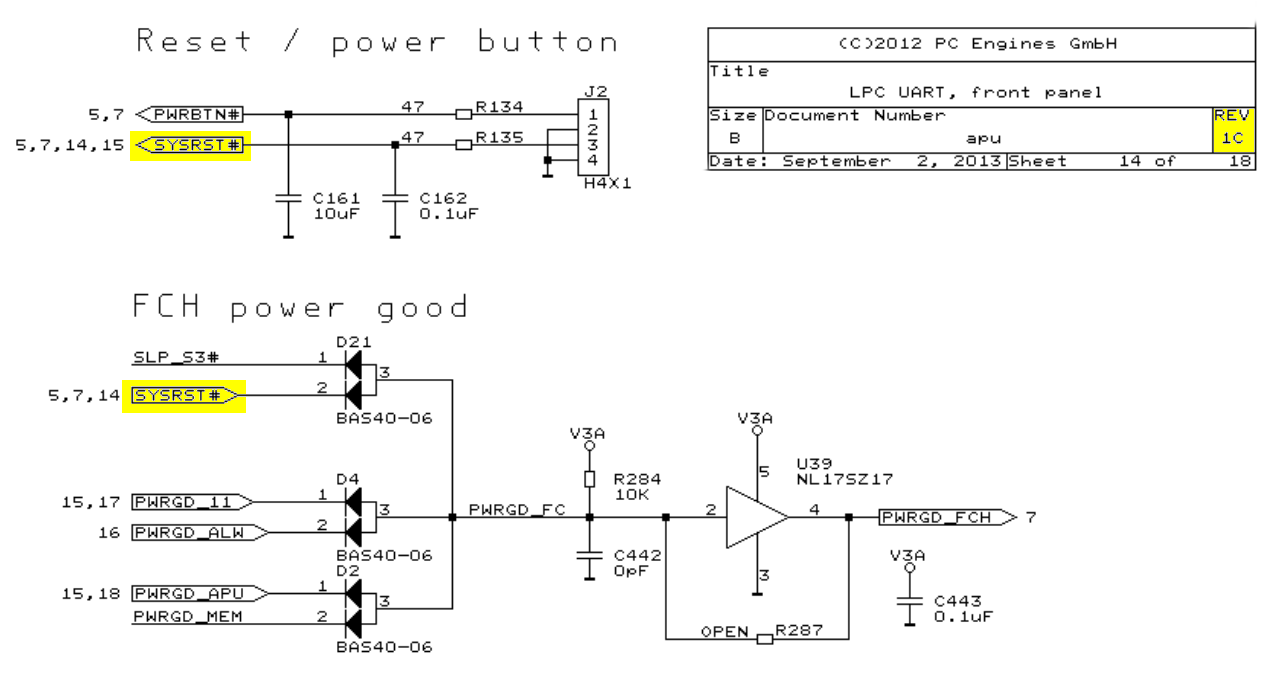
APU1C Reset schematic
Man erkennt im ersten Schaltplan (APU1C), dass der Reset-Button an einer 4×1 Pinleiste J2 auf Pin3 lieg. Der Reset soll wohl durch einen Taster erfolgen, der Pin3 und Pin4 verbindet.
Um zu verstehen was dabei passiert, muss man aber auch auf Seite 15 nachsehen. Das Signal ist nämlich nicht nur mit dem RESET# Eingang der CPU der APU verbunden, sondern auch mit dem Power-Good Kreis. Wir sehen, dass das Reset-Signal über die (doppelte) Diode D21 geleitet wird (Erinnerung: wird auf Masse gezogen!) und auf den Eingang des Schmitt-Triggers U39 läuft. Dazwischen ist ein 10kΩ Pull-Up Widerstand zu erkennen (R284). Dieser sorgt dafür, dass bei Vorhandensein einer Versorgungsspannung das PWRGD_FC Signal auf Versorgungsspannung gezogen wird. Gleichzeitig werden über die Dioden aber auch alle anderen verbundenen Signale auf etwa 3V gebracht, auch unsere SYSRST# Leitung. (Über der Diode fallen laut Datenblatt etwa 0.3V ab.)
Der Schmitt-Trigger (Wikipedia) U39 auf der rechten Seite sorgt dafür, dass aus dem Signal PWRGD_FC wieder ein sauberes Logiksignal PWRGD_FCH wird. Das ist wichtig, weil über die Dioden D2, D4 und D21 verschiedene Signale gemischt werden und zwischen 0.8V und 2V nicht definiert ist, ob es sich um HIGH oder LOW handelt. Siehe nochmal Logikpegel zur Verdeutlichung, mehr dazu auch gleich nochmal.
Schauen wir also, was im Fall eines (manuellen) Resets passiert: Nehmen wir also an, Pin3 und Pin4 an J2 sind verbunden. Dann wird der Kondensator C162 über den 47Ω Widerstand R135 entladen. Dies löst unmittelbar einen Reset der CPU aus, da SYSRST# direkt am Prozessor anliegt. Über die Diode D21 wird außerdem das PWRGD_FC Signal auf Masse gezogen, das vorher von R284 über 10kΩ mit der Eingangsspannung V3A verbunden ist. Damit ist dann auch PWRGD_FCH auf LOW. Hinweis: Es können hier knapp 70mA durch den Taster fließen, bei 3.3V und 47Ω, wenn auch nur kurz!
Wird der Taster losgelassen, so lädt sich der Kondensator C162 über die Diode D21 und den 10kΩ Widerstand R284 wieder auf und sobald die Schwelle des Schmitt-Triggers erreicht ist wird auch PWRGD_FCH wieder HIGH und das Board startet. Der RESET# Eingang der CPU wird in der CPU auch auf einem Schmitt-Trigger enden, so dass die CPU dann auch wieder startet. Ein Problem kann dabei sein, dass auf Grund der Diode D21 die Spannung am SYSRST#-Pin um etwa 0.3V unter der Spannung am Schmitt-Trigger der Power-good Schaltung liegt. Es kann also eventuell sein, dass die CPU schon läuft, während Speicher und Co noch außer Gefecht sind.
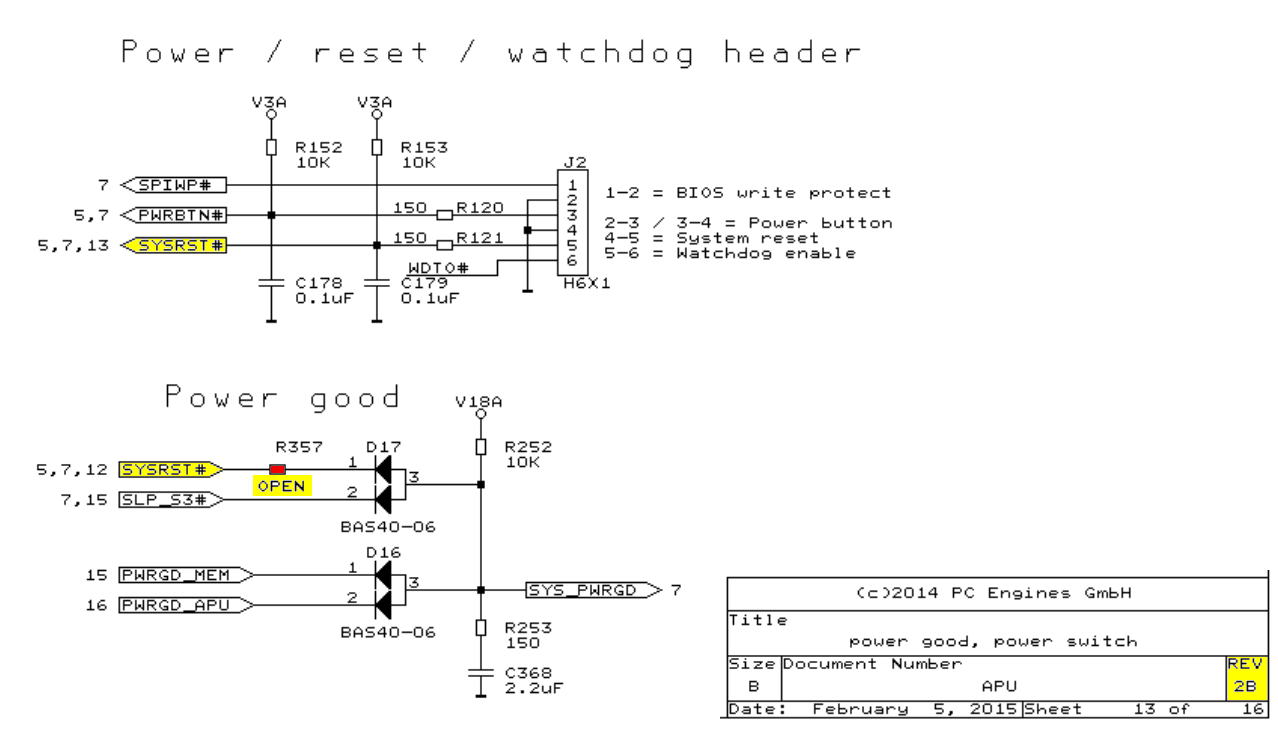
APU2 Reset schematic
Ein Blick in den Schaltplan der APU2 Reihe zeigt nun witzigerweise, dass SYSRST# und SYS_PWRGD nicht mehr miteinander verbunden sind – es gibt einen nicht bestückten Widerstand R357. Der Taster ist immer noch über einen Kondensator nach Masse entprellt, aber der Widerstand wurde auf 150Ω erhöht. Das begrenzt den Entladestrom über den Taster auf etwa 23mA.
Falls mir jemand erklären kann, warum sie bei den neuen Boards eine Brownout-detection einbauen und mit dem PWRBTN# Eingang des SOC verbinden und nicht mir PWRGD oder SYSRST#, würde ich mich freuen.
Externer Reset
Kommen wir nun zum eigentlichen Thema des Blogposts. Ich hatte ja angedeutet, dass ich etwas ausholen werde.
Es gibt mehrere Rahmenbedingungen, die beachtet werden müssen. Zum einen der Logikpegel des Geräts, mit dem der Reset ausgelöst werden soll, aber auch Robustheit gegen Störungen und versehentliche Fehlbedienung und elektrische Sicherheit – man will ja nicht dass die APU in Rauch aufgeht.
Zunächst sollte man sich klar werden, dass man eine galvanische Trennung zwischen APU und dem auslösenden Gerät erreichen will. Nur wenn beide Geräte am selben Netzteil und idealerweise im selben Gehäuse untergebracht sind, würde ich darauf verzichten. Schon weil ein Defekt an einem Gerät nicht gleich das andere ins Jenseits befördern soll, auch Masseschleifen können Probleme verursachen.
Dann muss man schauen, welchen Logikpegel das auszulösende Gerät hat. Einige Arduino arbeiten mit 5V Pegeln auf den GPIO Pins, andere ebenso wie der RasperryPi mit 3.3V.
Und schließlich ist noch die Robustheit der Lösung zu bedenken. Wenn das Kabel an der APU verdreht wird oder ein neues APU-Modell auf den Markt kommt, sollte die Lösung immer noch funktionieren. Und das ist letztlich der Hauptgrund, warum ich die Lösung mit einem Relais vorgeschlagen habe. Das Relais verhält sich gegenüber der APU wie ein Taster, es ist verpolungssicher, man bekommt es sehr günstig fertig aufgebaut mit einem 3.3V oder 5V Eingang und man kann es leicht erweitern für mehrere APUs oder um den Power-Button ebenfalls zu steuern.
Im Detail
Welche Möglichkeiten gibt es nun also, einen Reset extern auszulösen, also den RESET Pin auf Masse zu ziehen?
- MOSFET oder Bipolar Transistor
- Optokoppler
- Relais
- Taster der durch ein Servo betätigt wird (nur der Vollständigkeit halber)
Transistor
Eine mögliche Schaltung ist ein bipolarer npn-Transistor, bei dem der Kollektor an den RESET-Pin und der Emitter an GND angeschlossen wird. Über einen Widerstand wird der Strom in die Basis begrenzt und je nach Logikpegel und Transistortyp muss dieser berechnet werden. Nachteile sind: der Eingang ist empfindlich gegen statische Aufladung, man sollte ihn also mit einem Kondensator und Pulldown Widerstand sichern, um nicht versehentlich einen Reset auszulösen. Verwendet man einen MOSFET ist dies noch kritischer, da hier keine Ströme ins Gate fließen müssen um zu schalten.
Nachteile sind außerdem die fehlende galvanische Trennung und dass bei einem Verpolen des Steckers kein Reset erfolgen kann, da die Transistoren wie eine Diode nur in einer Richtung Strom fließen lassen. Ein Brückengleichrichter löst das Problem wegen des Spannungsverlustes über den Dioden übrigens nicht, man kann aber möglicherweise mit 2 FET eine Lösung finden, muss man aber auch ausrechnen und testen.
Hinweis: Der Transistor muss im Fall der APU1 sicher 70mA aushalten können die kurzzeitig aus dem Kondensator fließen können!
Ob die Lösung mit einer neueren APU oder einem anderen Gerät funktionieren wird: muss man im Einzelfall sehen.
Optokoppler
Ein Optokoppler bietet galvanische Trennung, ist unempfindlich gegen statische Aufladung oder offene Eingänge, allerdings ist er ebenfalls nicht verpolungssicher und man muss auch hier je nach Logikpegel den Vorwiderstand ausrechnen. Wäre in meinen Augen die sauberste Lösung, hat nur den Nachteil mit dem Verpolen – und nichts ist ärgerlicher als festzustellen, dass der remote-Reset nicht funktioniert und aus einer Lapalie wie kernel-update eine Rettungsmission mit 30 Minuten Anfahrt wird. Es sollte möglich sein zwei Optokoppler antiparallel zu schalten um eine Lösung zu finden die Verpolungssicher ist.
Aber auch hier gilt: Man muss passende Optokoppler finden, die Vorwiderstände berechnen und mit der APU testen. Bis zu 70mA sind kurzzeitig zu bewältigen und wenn andere Geräte angeschlossen werde sollen muss man gegebenenfalls wieder in die Designphase.
Taster und Servo
Für die ganz paranoiden – was als Druckluftschnellschalter in der Hochspannungstechnik existiert kann für uns nicht verkehrt sein oder so… Nein, einfach nur nein.
Relais
So sehr es mich wurmt, unter den gegebenen Voraussetzungen ist eine Lösung mit einer fertigen Relais-Platine mit Jumper um von 3.3V zu 5V Eingang umzuschalten die einfachste, robusteste und billigste Lösung.
Es ist kein Verpolen möglich, die APU wird wie vorgesehen von einem Taster in Form der Relaiskontakte zurückgesetzt, man kann auch andere Geräte damit zurücksetzen ohne vorher den Schaltplan zu studieren und ganz wichtig: die Platinen gibt es schon fertig für sehr kleines Geld zu kaufen.
Fazit
Nicht jede Lösung ist elegant, wenn sie robust sein muss – und manchmal sind 80% Lösungen die in 100% der Fälle funktionieren besser, also 100% Lösungen.