
The following text is a blogpost explaining my Diploma Thesis and the paper Exploring EDNS-Client-Subnet Adopters in your Free Time published in 2013.
The article was intended for publication in the corporate blog of one of the CDNs we studied, but after verizon bought the CDN the article never got published.
Mapping CDNs in your free time using EDNS and just one vantage point
Many CDNs (Content Delivery Networks) utilize DNS to infer the client location from the source of a DNS look-up to deliver the requested content from servers located close to the end-users.
The basic assumption here is, that the client is located near its resolver and that the geographic location is often ‚good enough‘, the network location cannot be known.
With more and more users using services like Google Public DNS or OpenDNS, instead of their respective ISP resolvers, this assumption does not any longer hold.
The result is a suboptimal end-user to server assignment and degradation of end-to-end performance for the clients. A solution to overcome the problem of clients being mis-located was proposed to the IETF in January 2011 by the consortium „A faster Internet“, which consists by some of the key players in the area such as Google, OpenDNS and large content providers, including EdgeCast.
The consortium developed an extension to the DNS called „Client-Subnet information in EDNS“ (ECS).
The idea is simple but effective: By adding IP-level information about the client to the DNS request, the client network location is made available to the authoritative nameserver.
This information can then be again used by the mapping system of the CDN to select appropriate content servers and send an according DNS reply back to the user. The answer will contain a scope, which allows for caching of the answer for other clients in the same network location.
Exploiting the EDNS extenstion for measurements
In our work we show that this mechanism can also be exploited to map the CDN server distribution and, in parts, client to server mapping.
Now, how is this possible you may ask – the answer is astonishing simple, there is one inherent limitation in the protocol: The authoritative nameserver has to trust the subnet information presented in the DNS request, which is nothing more than a specially crafted ‚Additional Section‘ in the DNS request, using EDNS.
This allows us to send DNS requests that, for the CDNs using EDNS, seem to originate from any chosen network, simply by setting the Client-IP-Subnet field accordingly. Notably this ‚attack‘ uses the protocol exactly as specified – and how the public DNS providers are using it.
For our experiment we first collected all publicly announced IPv4 prefixes from RIPE RIS and Routeviews. These will later be used as client prefixes. By using only these prefixes we can reduce the number of queries drastically and still get a good overview of the client-mappings. Also we are only interested in IP-space that is actually in use, which pretty much correlates to the announced prefixes.
All of these prefixes are collected in a central database and updated regularly, at least before each experiment run. This enables us to analyze how changes in the announcements possibly effect the results.
Our database also contains data from other datasources, like popular resolvers and prefixes of an ISP to be able to find possible special attributes in the mappings of these IP-ranges to CDN-servers.
For all these prefixes we then send a limited number of ECS enabled DNS requests to resolve hostnames that are known to host content on different ECS enabled CDNs. For Google this would be resolving the hostname www.google.com using ns1.google.com. We repeat the experiments several times over several months and all results, including the returned scope, have been recorded in our database.
For each adopter the result is a mapping of all IPv4 subnets, announced via BGP on the Internet, to web server IPs of the CDN providing the content for clients in these mapped networks.
One important aspect of this extension is the impact on caching. As mentioned the responses are now tied to the client prefix present in the request and not to the source IP address of the request any more. This means that a caching nameserver that is handling different client networks will now receive different answers – and would have to cache them all independently. To allow more efficient caching schemes, the extension adds a scope to the answer. This scope, when applied to the client prefix sent like a netmask, thus defines the IP-range the answer is valid for.
Looking at this property gives us a first insight into the operational practice of the CDNs.
Interpretation of the results
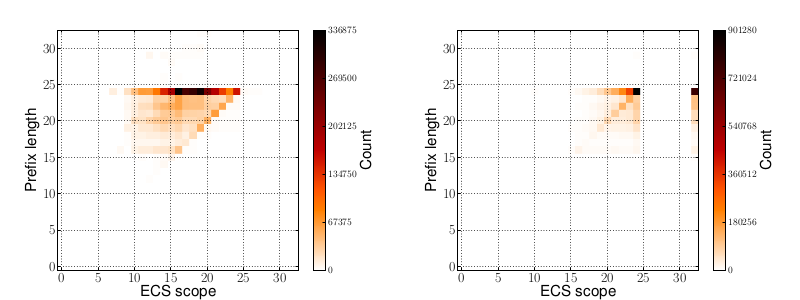
Fig. 1: EdgeCast on the left aggregates, Google on the right deaggregates networks.
Figure 1 shows two heatmaps where on the X-axis you see the scope returned by the nameservers and on the Y-axis the client prefix length sent to the servers. It can be seen that the two CDNs behave quite differently here.
On the left plot you see how with EdgeCast networks are being aggregated, allowing for efficient caching on the recursive resolver. In contrast Google on the right is often returning more specific networks, resulting in different result sets for given client networks. On a larger fraction you will even find a scope of 32 being returned, making the answer host-specific. Depending on the client networks served and the configuration of the CDN this behavior can lead to a higher cache miss-rate on nameservers, if the cache size is not increased.
Observing infrastructure changes
When taking a closer look at the actual A-Records returned we can make another interesting observation. Lets start by looking at some figures.
| Date | IPs | Sub- nets |
AS# | Countries |
|---|---|---|---|---|
| 2013-03-26 | 6340 | 329 | 166 | 47 |
| 2013-03-30 | 6495 | 332 | 167 | 47 |
| 2013-04-13 | 6821 | 331 | 167 | 46 |
| 2013-04-21 | 7162 | 346 | 169 | 46 |
| 2013-05-16 | 9762 | 485 | 287 | 55 |
| 2013-05-26 | 9465 | 471 | 281 | 52 |
| 2013-06-18 | 14418 | 703 | 454 | 91 |
| 2013-07-13 | 21321 | 1040 | 714 | 91 |
| 2013-08-08 | 21862 | 1083 | 761 | 123 |
As mentioned we repeated our experiments several times, over a period of 6 months, and by chance we were able to observe how rapidly Google was increasing the number of global Google caches visible in the Internet during that period.
Table 1 shows, how massive the infrastructure of Google has changed during our experiments – we notice a spike in the number of ASes that host Google front-end servers and a massive increase in countries where infrastructure is being operated. Note that the majority of ASes discovered are operated not by Google but, e.g. by ISPs. This means we are able to uncover these caches located in external networks with measurements conducted not from within these ISPs. By locating the client prefixes we can also map the distribution of CDN servers worldwide.
Conclusion
Our experiments show, that a single commodity desktop PC in one vantage point is sufficient to do this mapping within only a couple of hours, despite limiting the number of requests per second to a reasonable amount to avoid any serious impact on remote services. Adding more vantage points did not reveal significant more CDN servers.
Currently it seems, that this extension to the DNS is the only way a CDN can efficiently map clients using public DNS servers to the optimal servers. At the same time this extension is not officially accepted by the IETF and according to the discussions in the respective working group never will be. While it is shown that the ECS extension indeed gives better performance to end-users – and is the only solution for CDN operators relying on DNS to map clients to the ‚best‘ server locations again, this does not come without a price.
However, it is possible for competitors or attackers to find out where the CDN servers are deployed, how fast the infrastructure grows (or shrinks) and what clients are mapped to which locations. This can either be used to bootstrap a CDN or, in the worst case, by an attacker to enumerate all servers and craft directed attacks or circumvent geo-fencing. Currently the protocol alone can not prevent these kind of attacks.
Link to the paper: http://conferences.sigcomm.org/imc/2013/papers/imc163s-streibeltA.pdf.
The author earned a Diploma degree in Computer Science from Technical University Berlin in 2013 and is a PhD candidate in the Internet Network Architectures group at Technical University of Berlin under the supervision of Anja Feldmann.